When implementing $O(N^3)$ operations like matrix multiplication in C++, computational complexity is only half the picture. The physical architecture of the CPU memory hierarchy dictates execution speed just as much as the algorithm itself.
By analyzing how the CPU interacts with the L1 cache, we can optimize memory access patterns to yield massive performance gains without changing the underlying mathematical logic.
Understanding the L1 Cache
To understand the optimization, you need a baseline understanding of CPU caching.
Main memory (RAM) is exceptionally slow compared to the CPU’s processing speed. To prevent the CPU from stalling while waiting for data, modern processors use a hierarchy of smaller, ultra-fast memory caches (L1, L2, L3) located directly on or near the CPU die.
The L1 cache is the smallest and fastest of these. When the CPU requests a variable from RAM, it doesn’t just fetch that single variable. It fetches a contiguous block of memory (a “cache line,” typically 64 bytes) and stores it in the L1 cache.
If your program subsequently requests the next sequential memory address, the CPU already has it in the L1 cache. This is called a cache hit (extremely fast). If your program requests a distant memory address, the CPU must fetch a new block from RAM. This is a cache miss (extremely slow). Maximizing cache hits by accessing memory sequentially is known as spatial locality.
The Inefficient Approach (Strided Access)
In C++, std::vector stores data in row-major order—meaning elements of a row are stored contiguously in memory.
Here is the standard i-j-k loop ordering for matrix multiplication:
// eg2.cpp
#include <iostream>
#include <vector>
#include <chrono>
using namespace std;
int main() {
// Matrix - x,y,z
int x_rows = 2048;
int x_cols = 2048;
int y_rows = 2048;
int y_cols = 3500;
vector<int> x(x_rows * x_cols);
vector<int> y(y_rows * y_cols);
vector<int> z(x_rows * y_cols);
cout<<"x len -> "<<x.size()<<endl;
cout<<"y len -> "<<y.size()<<endl;
for(int i=0;i<x.size();++i) x[i]=i;
for(int i=0;i<y.size();++i) y[i]=i;
auto start_time = chrono::high_resolution_clock::now();
for(int i = 0; i < x_rows; ++i) {
for(int j = 0; j < y_cols; ++j) {
int sum = 0;
for(int p = 0; p < x_cols; ++p) {
sum += x[i * x_cols + p] * y[p * y_cols + j];
}
z[i * y_cols + j] = sum;
}
}
auto end_time = chrono::high_resolution_clock::now();
chrono::duration<double> tt=end_time - start_time;
cout<<"Time taken: "<<tt.count()<<" secs"<<endl;
return 0;
}
In the innermost loop, p increments. The access pattern for y[p * y_cols + j] forces the pointer to jump by y_cols (e.g., 3500 integers) on every iteration. This strided access completely destroys spatial locality, resulting in constant L1 cache misses.
The Optimized Approach (Sequential Access)
By swapping the two inner loops, we change the access pattern to align with how C++ stores data in memory:
for (int r = 0; r < x_rows; ++r) {
for (int p = 0; p < x_cols; ++p) {
for (int c = 0; c < y_cols; ++c) {
z[r * y_cols + c] += (x[r * x_cols + p] * y[p * y_cols + c]);
}
}
}
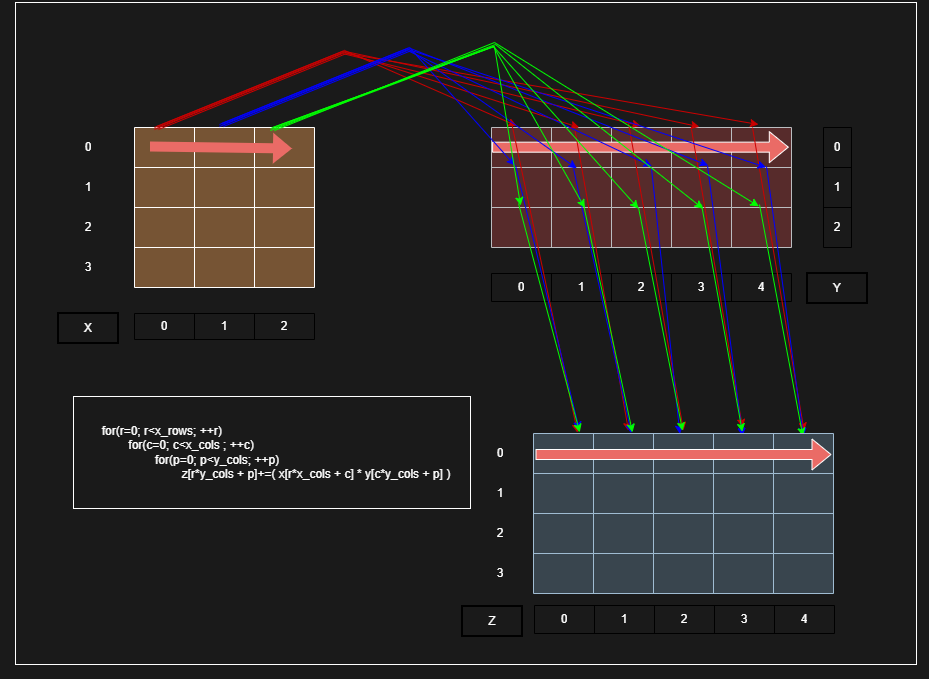
In this r-c-p configuration, the innermost loop increments p. The arrays y and z are now accessed sequentially (... + p).
Here is a visual representation of this memory access pattern:
As shown in the diagram, as the innermost loop executes, it traverses straight across the rows of matrix Y and matrix Z. Because this exactly matches the row-major memory layout, the CPU pulls a 64-byte cache line once, and the next several iterations are guaranteed cache hits.
Empirical Results
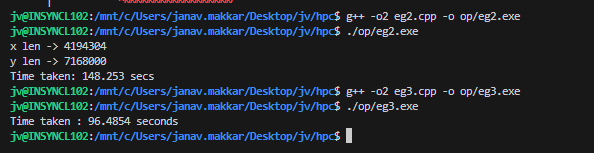
The difference in execution time is substantial. Compiling both versions using GCC with the -O2 optimization flag yields the following results on a 2048x2048 and 2048x3500 matrix:
- Standard (
eg2.exe): 148.25 seconds - Optimized (
eg3.exe): 96.48 seconds
By simply rewriting two lines of code to respect spatial locality and the L1 cache, the execution time was reduced by roughly 35%, entirely bottlenecking on compute rather than memory latency.
Full Optimized Code:
// g++ -O2 eg3.cpp -o eg3.exe
#include <vector>
#include <iostream>
#include <chrono>
using namespace std;
int main()
{
int x_rows = 2048;
int x_cols = 2048;
int y_rows = 2048;
int y_cols = 3500;
vector<int> x(x_rows * x_cols);
vector<int> y(y_rows * y_cols);
vector<int> z(x_rows * y_cols);
int value;
int i;
for (value = 1, i = 0; i < x.size(); ++i, value++) x[i] = value;
for (value = 10, i = 0; i < y.size(); ++i, value++) y[i] = value;
for (int c = 0; c < z.size(); ++c) z[c] = 0;
int r, p, c;
auto start_time = chrono::high_resolution_clock::now();
for (r = 0; r < x_rows; ++r){
for (p = 0; p < x_cols; ++p){
for (c = 0; c < y_cols; ++c){
z[r * y_cols + c] += (x[r * x_cols + p] * y[p * y_cols + c]);
}
}
}
auto end_time = chrono::high_resolution_clock::now();
chrono::duration<double> tt = end_time - start_time;
cout << "Time taken : " << tt.count() << " seconds" << endl;
return 0;
}
Results